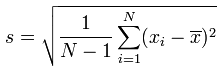Since I need training in bash scripting, plus it is kind of a simple thing to do - I decided to write it as a bash script.
It is dead simple to schedule a task. It can be run once or periodically.

Sorry for the image being in swedish, the language settings did affect gmail but not google calendar. Anyway, the procedure is as follows.
- Install the googlecl tools. Use it with your calendar so that you are forced to complete the verification procedure. (i.e $ google calendar today).
- Fire up google calendar and create a new task.
- Enter a title for the task. The title must begin with gcmd for the scheduler daemon to pick it up.
- Enter the start and finish times (currently the time range cannot span over several days).
- In the "where" field, start with the flag -i followed by the interval with which to run the task (in seconds, 0 to only run it once).
- Continue by adding -- which means "end of arguments".
- Finish up by entering your command of choice last. Note that the initial run is scheduled using at, which does not have any PATH variable set. In other words, give full path names.
- Run the gcmd script.
It is probably best to schedule the gcmd script to run every minute or so using crontab to have it catch the updates when you're adding tasks at work, the bus, the car, the empire state building, you get the point.
Let's look at the script. It's quite commented so I don't feel a need to explain anything further.
gcmd#!/usr/bin/env bash # 1. Get todays tasks from google, grab only those starting with gcmd. # Loop over the different tasks.google calendar today --fields "title,where,when,id" \ | awk -F, '/gcmd/' \ | while read line; do# 2. Default args. These are overridden by args read from the # where field of the task.# Interval between executions, 0 to only run once. interval=0# 3. Get arguments from the where field and overwrite default values.set -- $(getopt i: "$(echo "$line" | awk -F, '{print $2}')") while [ $# -gt 0 ]; do case "$1" in (-i) interval=$2; shift;; (--) shift; break;; # Terminates the args (-*) echo "$0 error - unrecognized arg $1" 1>&2; exit 1;; (*) break;; esac shift done# 4. Get the unique ID and construct a filename of it. The id is displayed # as a URL, ending with a unique id.arr=($(echo "$line"|awk -F, '{print $4}'|tr "/" " ")) filename="/tmp/.gcmd_${arr[${#arr[@]} - 1]}" command="$*"# 5. If the job has already been scheduled, un-schedule the job and # remove the fileif [ -e "$filename" ]; then echo "File exists, re-scheduling" atrm $(cat "$filename") else echo "New job \"$(echo ${line}|awk -F, '{print $1}')\"" fi# 6. Get the desired time to run/stop. This should be improved to account for # date aswell. Currently we only parse the time, which isn't enough if we need # to run the task for several days.time="$(echo ${line}|awk -F, '{print $3}'|awk -F- '{print $1}'|awk '{print $3}')" stoptime="$(echo ${line}|awk -F, '{print $3}'|awk -F- '{print $2}'|awk '{print $3}')"# 7. If an interval is specified, make the command run according to the interval specified. # This can be improved since it doesn't take into account how long the job takes to run so # the interval will be more like interval + time to run task.if [ $interval -ne 0 ]; then command="stoptime=$(date -d ${stoptime} +%s); gcmdfun() { ${command}; }; while [ \$(date +%s) -lt \$stoptime ]; do gcmdfun; sleep $interval; done;" fi# 8. Schedule the command to run using at and store the job number in a file (named by the unique id).echo "$command" | at "$time" 2>&1 | awk '/job/{print $2}' > "$filename" done
It's late over here now. Enjoy and Good night!