Unlike many other IT tutorials I will be keeping this tutorial short and concise and get to the most basic and interesting stuff right away by a short example.
Imagine you have a CSV file containing statistical data of a group of people containing their IQ and their age, like so (file could actually be thousands of lines long):
data.csv
123,34
119,23
100,56
Now what I like to do is to find the mean age, mean IQ and standard deviation for them both and output them in structured way. Seems like lots of lots of code? Not with awk!
We start off by making a simple script that calculates the mean values for both columns, look at the code below.
script.awk
BEGIN {
sum_iq=0;
sum_age=0;
}
{
sum_iq = sum_iq + $1;
sum_age = sum_age + $2;
}
END {
print "Mean IQ: " sum_iq/NR;
print "Mean age: " sum_age/NR;
}
Execute the following to test the script:
$ cat data.csv | awk -F, -f script.awk
This pipes the contents of data.csv to awk, which is run with the field terminator , (comma) and script file script.awk.
To explain what is happening in the script you have to know that awk is designed to be executed on batches of lines of text (i.e. text files). For each line in the file, the script is executed - retaining its variables values. Awk scripts are organized in the form.
pattern{action}
When a pattern is matched, the action (stuff between the curly braces) are executed. A pattern can be a keyword like BEGIN or END as we use here, completely empty (matching every line) or a regular expression contained between two forward slashes.
So what happens in our script is the following:
- The first line is fed to the script, since this is the first line the pattern BEGIN is matched. Within the block we set the variables sum_age and sum_iq to 0.
- Still on the first line but now the second curly-brace-block is matched (remember, it matches every line). Inside the block we add the value from the first column to the sum_iq variable and the value from the second column to the sum_age variable.
- The rest of the lines are matched and added to the sum variables.
- On the last line the END pattern is matched. Here we simply print out the sums divided by the keyword NR which is awk's line counter. Anywhere in the script it can be used as a variable, telling us on which line we are, special case is the last line - in this case NR tells us how many lines the file has.
Just to show off we can add a standard deviation calculation like this.
BEGIN {
sum_iq=0;
sum_age=0;
}
{
sum_iq = sum_iq + $1;
sum_age = sum_age + $2;
iq[NR] = $1;
age[NR] = $2;
}
END {
mean_iq = sum_iq/NR;
mean_age = sum_age/NR;
stdd_iq = 0;
stdd_age = 0;
for(i=1; i<=NR; i++) {
stdd_iq += (iq[i] - mean_iq)**2;
stdd_age += (age[i] - mean_age)**2;
}
stdd_iq = sqrt(stdd_iq/(NR-1));
stdd_age = sqrt(stdd_age/(NR-1));
print "Mean IQ: " mean_iq " (" stdd_iq ")";
print "Mean age: " mean_age " (" stdd_age ")";
}
A simple estimation of standard deviation on an observed set is
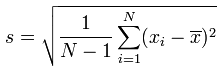
You should not that there is no checking for blank or invalid lines in this code, that's an exercise for the reader.
Make sure to check out this awesome and much more in-depth tutorial on awk: http://www.grymoire.com/Unix/Awk.html
For some really cool examples and ideas, this blog is number one:
http://www.thegeekstuff.com/tag/awk-tutorial-examples/
I hoped you enjoyed this little tutorial and post some links to my brand new blog all over the internet ;)
No comments:
Post a Comment